Deploying a Faktory worker to AWS Fargate
Looking for a fresh, 2018 approach to deploying a Rails app to AWS? We've partnered with DailyDrip on a series of videos to guide you through the process. We're covering how to Dockerize a Rails app, AWS Fargate, logging, monitoring, setting up load balancing, SSL, CDN, and more.
In the previous post of this series, we deployed the
Setting Up Our Worker Service
We need to set up a new task definition for our worker service, but it will use the same image our Rails app (the
Let's start by pushing up our new image.
➜ docker build -t production . ➜ docker tag production:latest 154477107666.dkr.ecr.us-east-1.amazonaws.com/dailydrip/produciton ➜ docker push 154477107666.dkr.ecr.us-east-1.amazonaws.com/dailydrip/produciton:latest
Now, let's create our new task definition. Since we're using the same underlying image and we'll need to set up the same environment variables, it'll be easier to create our new task definition based off of the existing web task definition we created a few videos back.
Before we do that, we need to set up a couple of new environment variables on our existing web task definition.
For that, we need to select the latest version of our Web task definition and Create new revision
Once we're in the configuration page, we need to scroll down and select produciton
GMAIL_USERNAME:<email_address>GMAIL_PASSWORD:<password>FAKTORY_URL:tcp://:password@172.31.8.138:7419(this is the internalip for ourfaktory task)FAKTORY_PROVIDER: FAKTORY_URL- Note:
FAKTORY_PROVIDERis needed in the current version of thefaktory worker ruby gem we are using, but in the current master branch it is not required. It only references the environment variable that theFaktory service's URL is set to.
- Note:
Once we've added that, we can save the new revision of our web task definition.
Now, we can move on to creating our new task definition for our worker service. Let's start by selecting the latest revision of our web app task definition and Create new revision
From here, we need to change two things. First, we need to change the name of our task definition worker
Once we are in the model for our container settings, we need to set the command bundle,exec,faktory-workerUpdateCreate
We should now have a new task definition named worker, and we can move on to creating our new service for the worker.
Creating the Service
Now that we have our task definition set up, let's create our worker service. To do that, we need to navigate over to our Clusters dashboard and Create
We're going to choose these options (leaving the rest as their defaults) to create our service:
- Launch Type:
Fargate - Task Definition:
worker - Service name:
worker Number of tasks:1
Then, Next step
For our network settings, we're going to choose:
- Cluster VPC: The same cluster VPC that was used to configure our other services.
- Subnets: The same subnet that was used to configure our other services.
Then, Next Step
For our Auto Scaling, we'll leave it at the default and Next Step
Lastly, look over the configuration and make sure everything is correct and Create Service
After we've created our service, we can click View Service
We can follow the same steps above that we used to provide access to our Rails app. Once we've edited the rules, it should look similar to this.
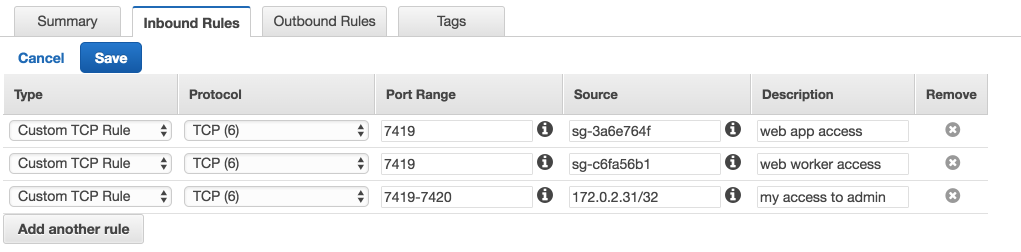
Now, we can restart our new service.
➜ aws ecs update-service --service worker --cluster Produciton --force-new-deployment
After a moment, we can navigate back to our AWS console and see that our worker service is now running.
We can verify that we've successfully connected to the
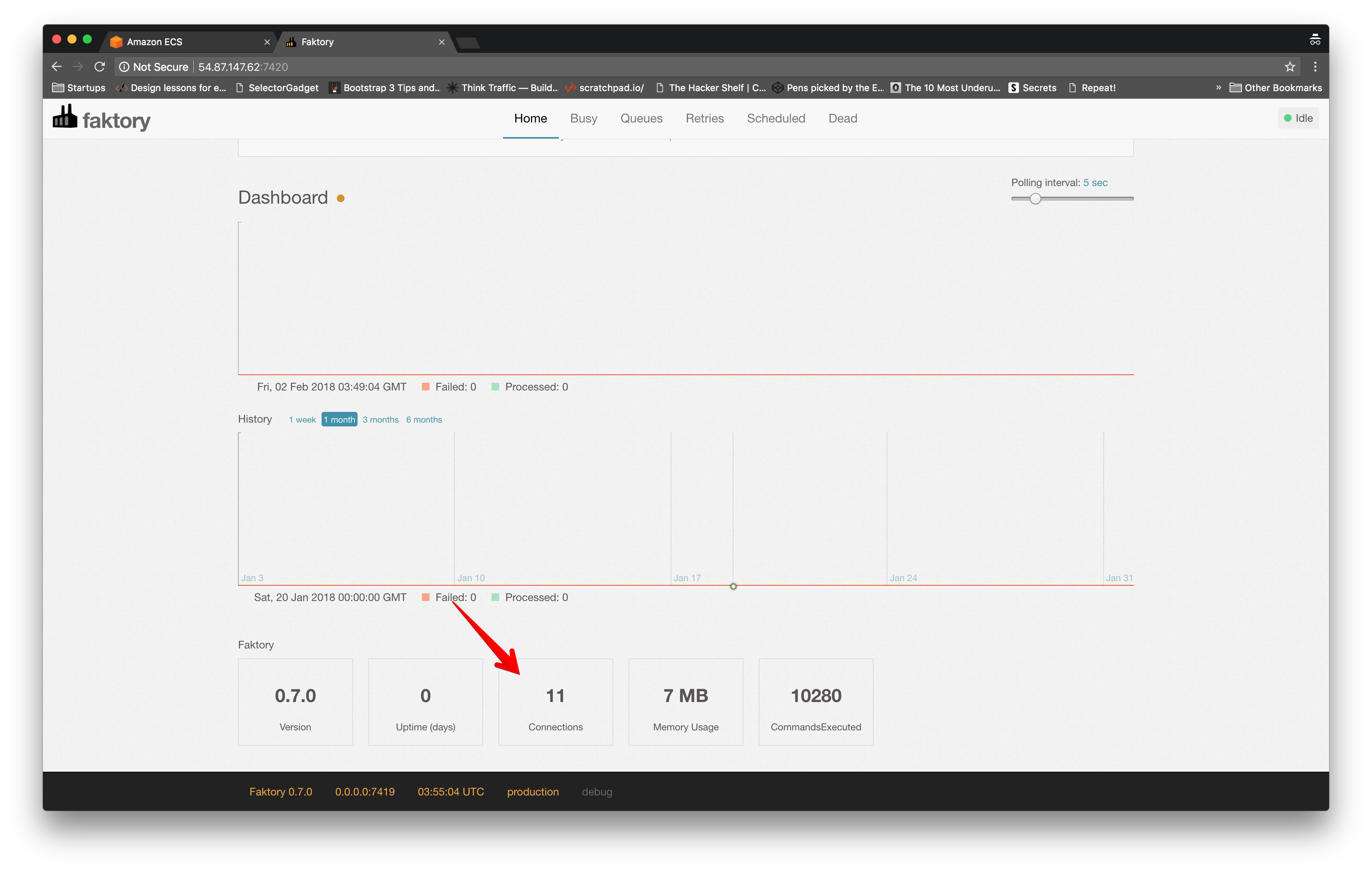
We can also go into our Rails app, try to share a checklist, and verify that the action triggers a new background job.
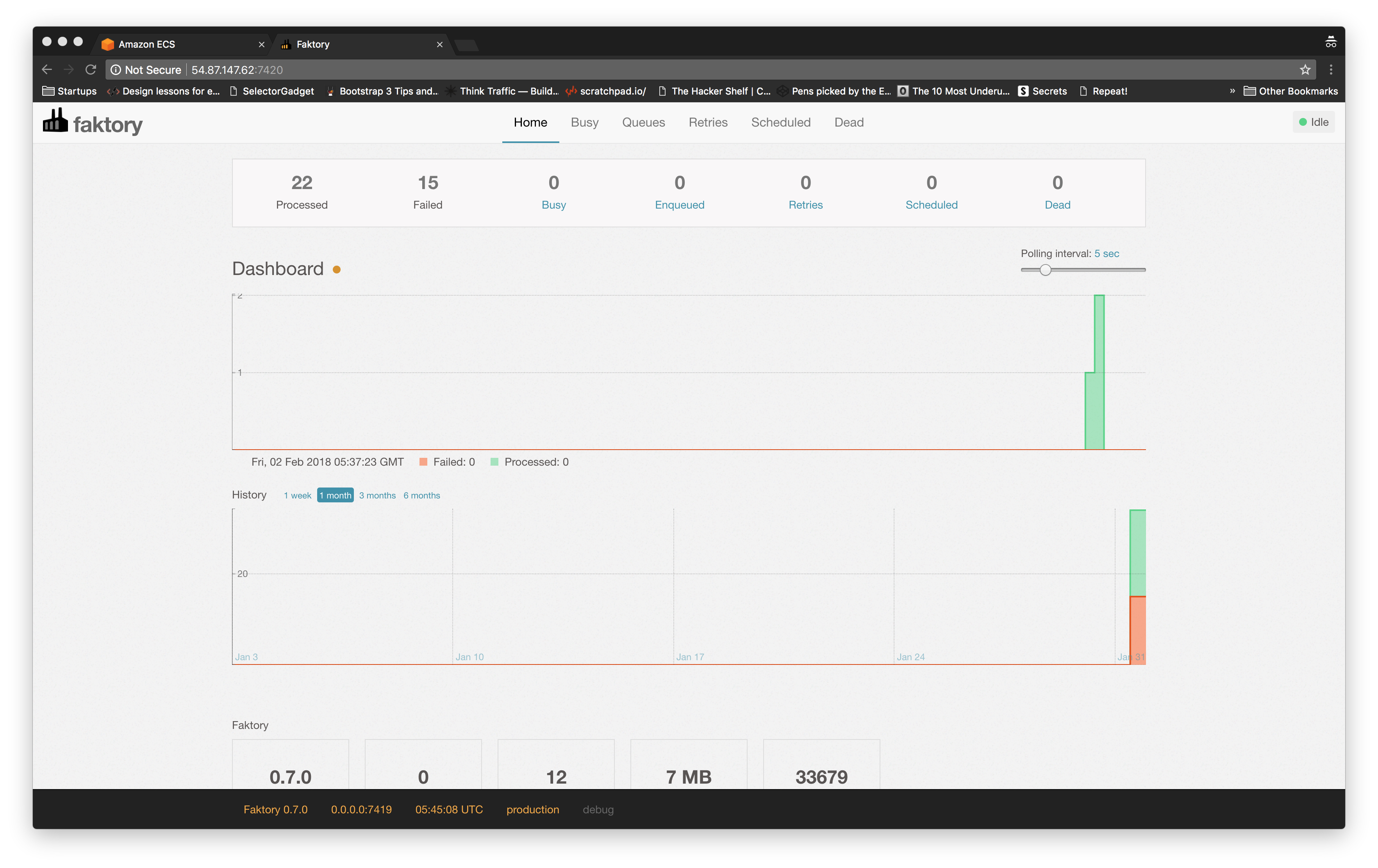
Oops! It looks like we forgot to give our worker service access to our database.
Let's correct that and try again.

As you can see, there were a few
But now, we're finally able to run background jobs! Yay!
What's left to the reader?
Today we cloned our existing web app tasks definition to create our worker task definition and set up a worker service.
However, with all that we've done, there are still a few more improvements that could be made for real production usage.
First, does it actually make sense to run
- As of now, we don't have a good way of pointing the other services (web/worker) to it outside of using the internal IP address. We could have put the service behind a load balancer, but that doesn't really make
sense, since we're not going to run more than one instance ofFaktory . - With the current configuration, if we have to restart the
Faktory service, it will get a new IP address assigned and we'll need to update the task-definition for both the web app and worker. - We didn't mount an external volume and use that as the data store for
Faktory . So, if you were to restart theFaktory service, you would lose any jobs left in the queue. That can easily be fixed by mounting a volume on theFaktory container and updating the configuration settings whereFaktory stores all its data.
I hope you've enjoyed learning some of the basics of setting up




