AWS Disaster Recovery: Configuring a Read Replica and a Multi-AZ
We've partnered with DailyDrip on a two-part series guiding you through Automated Backups and Disaster Recovery on AWS. This is part 2. You can read part 1 here.
This is the second portion of a two-part series on automated backups and disaster recovery for AWS. In part 1, we summarized the main options: database snapshots, read replicas, and multiple
Read Replica
Let's discuss replicas.
As we mentioned in part 1, in a replica configuration, you have the concept of a master and slave. The master is the primary database where the application is writing data. The master then propagates the changes to the replica. The method of propagation is usually asynchronous, utilizing transaction logs, but can be synchronous as well.
There are several benefits of using a read replica:
- Minimizing downtime - If you only utilize database backups as part of your disaster recovery plan (DRP) and you have a database failure, you will have to plan for a longer window of downtime. However, with a read replica, if the master fails, a slave can be promoted to master and your app will continue to run.
- Split up reads between databases - If your application produces lots of database lookups for reporting purposes, it may make sense to offload some of those reads to a slave server, allowing your master to stay performant. Although we won't be covering that in this video, there are Ruby gems like
octopus that allow you to easily support multiple databases for these type of scenarios.
Now, let's take a look at setting up a read replica.
Setting up a replica
If we head back over to the RDS dashboard and go to the instances pages, we should see Instance ActionsCreate Read Replica
At this point, we should be on a page similar to the page we used to create our initial database.
Most of the settings we will leave at their default. If we were going to leave this replica in place, we would preferably change the availability zone to be in a different region than our test database. But, since this is not going to be kept, we're going to leave it to the default.
What we will be changing is DB Instance Identifiertest-replicaCreate Read Replica
This will return us to the test database instance page. If we click Instances

After a few minutes, the replica should be available and we now have replication setup.
Testing replication
We can test this by connecting to our test DB, writing some data, and verifying that it shows up in our replica.
➜ ~ psql -Uroot -dtest -htest.cxywwt2zdqub.us-east-1.rds.amazonaws.com
test=> insert into todos (name) values ('configure replica');
➜ ~ psql -Uroot -dtest -htest-replica.cxywwt2zdqub.us-east-1.rds.amazonaws.com
test=> select * from todos;
id | name
----+-------------------
5 | configure replica
(1 row)
test=> insert into todos (name) values ('configure replica');
ERROR: cannot execute INSERT in a read-only transaction
As we see here, our replication is up and running and we are only able to read from our replica.
One last thing to note is that if the master were to go down, we can easily promote the slave by going RDS Dashboard > InstancesInstance ActionsPromote Read Replica
This will promote the replica, so it will no longer fetch changes via transaction logs.
Multi-AZ
Multi-AZ configuration is the last option we will discuss today.
In a Multi-AZ configuration, you'll need a minimum of two database instances in different availability zones. With this setup, we have the notion of a primary and standby.
There are some major differences between a Multi-AZ configuration and read replica:
- In a Multi-AZ configuration, data is distributed synchronously so that all of the instances have the same data at any given time.
- You can't use the standby to offload reads from an application. The standby is only there for failover.
Lastly, failover is handled automatically. So, if the primary goes down, AWS changes the DNS records to point to a standby. So, there is no manual interaction needed for failover.
Multi-AZ configuration is just as easy to configure as a replica (actually, easier). If you followed along in our previous videos, when we initially set up the
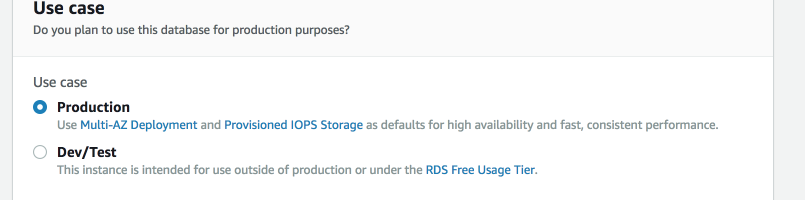
But, even if you select Dev/Test

After that, the remaining configuration is the same as any other instance.
Summary
In this video, we configured a read replica and a Multi-AZ. We've discussed some of the pros and cons of each and some of the reasons to use one over the other.
At the end of the day, your disaster recovery plan is going to be catered to the needs of your business or application. In certain cases, longer downtime windows might be acceptable. High availability may or may not be a concern and your application might not have the amount of traffic that justifies replication.
We've only scraped the surface of what's available in terms of data loss mitigation and resiliency. We've added a few resources below that have far more information regarding what's available in AWS. If you're interested in this topic, you should definitely spend some time looking through them.




