Getting down with Stackprof: how we added N+1 query detection to Scout
Let's get the confusing part out of the way: we're going to get a little "meta". This post is about using one performance tool (Stackprof) to improve another performance tool (Scout's Rails Agent) so Scout can diagnose a common performance pitfall (N+1 queries).
Did I just put "performance" in a sentence three times? You can see I'm a little obsessed.
There's plenty written about why N+1 queries are bad. Is there anything good about an N+1?
Yes! Finding an N+1 is like finding a $20 bill in your couch. It's a performance-enhancing gift and often an easy fix - assuming you can find the spot in your code that is emitting the query.
...and there-in lies the problem. It is difficult to trace problematic N+1 queries on complex apps running in production back to a line-of-code. In fact, I don't know of a tool today you can run in production that does this. Why is it difficult? Grabbing backtraces is not cheap - you can't call Kernel#caller all willy-nilly in your instrumentation. It means you are left with deadends like this when trying to track down an N+1:
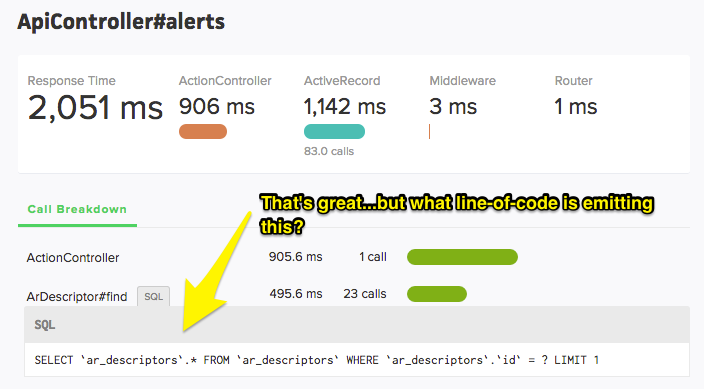
In the above screenshot, each ArDescriptor#find query executes quickly (22 ms), but there are 23(!) queries with the same SQL, adding up to nearly 500 ms.
Now, I don't know about you, but I find this incredibly frustrating. Armed with Stackprof, we set out to see: could we make it performant to find the source of N+1s with Scout?
Why finding the source of N+1 is hard
From an instrumentation perspective, it's easy to fetch a backtrace from single slow calls in a web request. Just see if the call took longer than some threshold and grab the caller info. Here's how we did this in Scout prior this experiment.
Collecting caller information isn't cheap. That's why the 500 ms threshold is in place in the linked code above. For giggles, I modified our agent to collect caller information on EVERY instrumented layer and measured against our representative endpoint benchmark. Here's how the numbers lined up:
| Benchmark Name | Response Time
(Mean)
|
Response Time
(95th Percentile)
|
Response Time
(Max)
|
Overhead |
|---|---|---|---|---|
| Existing Logic | 38.9 ms | 63.5 ms | 88.1 ms | |
| N+1 Experiment #1 | 65.8 ms | 100.83 ms | 131.7 ms | 69% |
Blindly grabbing the caller from every layer adds almost 70% more overhead - while this would solve tracking N+1s to their source, the medicine is worse than the disease.
Enter Stackprof.
Initial Stackprof Results
When I see poor results in a benchmark, I'll re-run it with Stackprof. Haven't heard of Stackprof? Stackprof is a sampling call-stack profiler for Ruby 2.1+. What's magical about including Stackprof in your performance workflow? If you're relying solely on benchmarking to improve performance, you'll often limit the scope of your work to one change at a time and compare the before-after. You don't have to do these controlled experiments with Stackprof. It's trivial to see what methods - even down to the LOC within methods - are consuming the most time.
Here's a snippet of the Stackprof results from the above experiment, filtered to just our agent (ScoutApm) from experiment #1:
stackprof tmp/stackprof_scout_memory/stackprof-wall-4*
==================================
Mode: wall(1000)
Samples: 3176013 (21.44% miss rate)
GC: 307766 (9.69%)
==================================
TOTAL (pct) SAMPLES (pct) FRAME
731697 (23.0%) 731697 (23.0%) ScoutApm::Layer#store_backtrace
...
778228 (24.5%) 192 (0.0%) ScoutApm::TrackedRequest#stop_layer
I've cut the frames outside of my modifications. Now, there's a little dancing with Stackprof...a little juking. It's not always a straight line to a problem: my change was in #stop_layer, not in #store_backtrace.
So, why isn't the extra overhead showing in #stop_layer? Let's zoom into #store_backtrace and see where all the samples are coming from:
stackprof tmp/stackprof_scout_memory/s* --method store_backtrace
ScoutApm::Layer#store_backtrace (/home/vagrant/.rbenv/versions/2.2.3/lib/ruby/gems/2.2.0/bundler/gems/scout_apm_ruby-74935344e8e3/lib/scout_apm/layer.rb:69)
samples: 731697 self (23.0%) / 731697 total (23.0%)
callers:
731697 ( 100.0%) ScoutApm::TrackedRequest#stop_layer
code:
| 69 | def store_backtrace(bt)
729999 (23.0%) / 729999 (23.0%) | 70 | return unless bt.is_a? Array
876 (0.0%) / 876 (0.0%) | 71 | return unless bt.length > 0
822 (0.0%) / 822 (0.0%) | 72 | @backtrace = bt
| 73 | end
return unless bt.is_a? Array, seems pretty trivial right? Why is this responsible for 23% of all samples?
Here's why: #stop_layer passes the caller to store_backtrace as parameter, but it isn't actually fetched until the above LOC. Stackprof can isolate samples to a single line, but we can't divide that line further. Lines are the lowest common denominator in Stackprof. So, rather than passing Kernel#caller to #store_backtrace, lets grab the result, then pass it through. More like this:

Here's what Stackprof gives us for ScoutApm::TrackedRequest#stop_layer now:
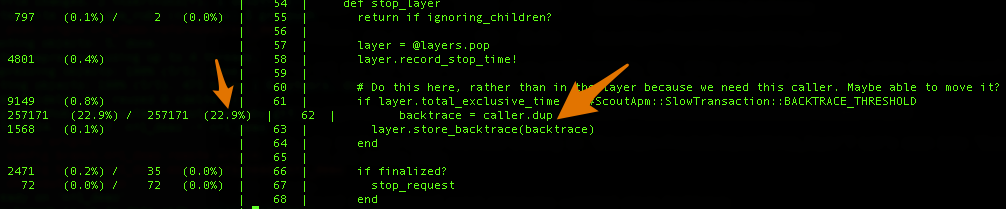
Now, that clarifies things. Our overhead is clearly in the caller collection.
Stackprofin' Lesson: if Stackprof points you to a LOC doing several things, divide that work into multiple lines.
Lookup Hash?
It's clear that blindly grabbing the caller for every layer is too expensive. However, the great thing about an N+1 query is that there's no reason to fetch caller information on repeated, identical calls. We really only need to do it once.
How about a lookup hash of a layer name (ex: "User find" for an ActiveRecord query) and the number of calls to it over the life-cycle of the request? We'll then only fetch caller information if there are 5 or more of the same SQL queries and the time between the start of the first call the current call exceeds 300 ms. Why 300 ms? We'll use that as a reasonable threshold for an N+1 query that has a ample potential to be optimized.
Here's the results of experiment #2:
| Benchmark Name | Response Time
(Mean)
|
Response Time
(95th Percentile)
|
Response Time
(Max)
|
Additional Overhead | |
|---|---|---|---|---|---|
| Existing Logic | 38.9 ms | 63.5 ms | 88.1 ms | ||
| N+1 Experiment #2 | 49.5 ms | 132.0 ms | 2,129 ms | 27% |
Well shoot - that's still 27% slower. How can that be? Stackprof anyone?
==================================
Mode: wall(1000)
Samples: 847204 (24.38% miss rate)
GC: 55050 (6.50%)
==================================
TOTAL (pct) SAMPLES (pct) FRAME
53959 (6.4%) 53959 (6.4%) ThreadSafe::NonConcurrentCacheBackend#[]
47493 (5.6%) 47491 (5.6%) ActiveSupport::PerThreadRegistry#instance
38160 (4.5%) 36597 (4.3%) ScoutApm::Utils::SqlSanitizer#sql
...
Well, that's odd...I didn't change anything in SqlSanitizer. So, what's calling this method? I'll run stackprof ... --method ScoutApm::Utils::SqlSanitizer#sql, and inspect the callers:
callers:
234994 ( 100.0%) ScoutApm::Utils::SqlSanitizer#to_s_postgres
15 ( 0.0%) ScoutApm::Utils::SqlSanitizer#to_s
I'll repeat on #to_s_postgres:
callers:
242865 ( 100.0%) ScoutApm::Utils::SqlSanitizer#to_s
And I'll keep going, this time with #to_s:
callers:
247727 ( 99.9%) ScoutApm::CallSet#update!
Boom! That is interesting - CallSet is the new class I created to track N+1 activity. I'll run stackprof ... --method ScoutApm::CallSet#update!:

Sidenote: why did I manually work through the callers vs. Stackprof's graphviz output? I find the generated call tree to large to read and slow to generate.
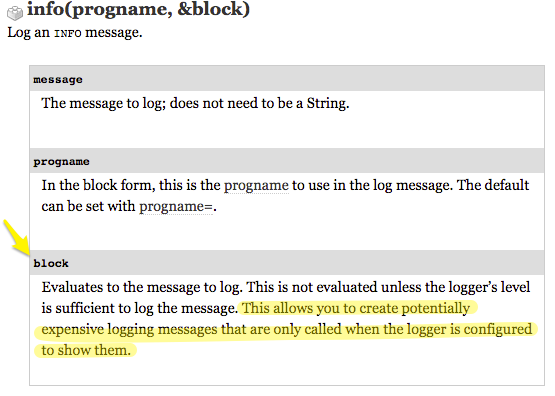
It's all coming from a line where I'm logging at the debug level, but I'm running logging at the info level. What gives? The contents of that string are being evaluated. I jump into the Logger docs and I see a helpful note...Logger can take a block. From the docs:
Back to the slow logging: I'll just pass a block thru vs. a String:
ScoutApm::Agent.instance.logger.debug { "Updating call set w/ [#{item}]" }
And re-run the benchmarks:
| Benchmark Name | Response Time
(Mean)
|
Response Time
(95th Percentile)
|
Response Time
(Max)
|
Additional Overhead | |
|---|---|---|---|---|---|
| Existing Logic | 38.9 ms | 63.5 ms | 88.1 ms | ||
| N+1 Experiment #3 | 40.6 ms | 64.8 ms | 82.3 ms | 4% |
That's less than 2 ms of overhead - a tradeoff I'll happily take to easily track down expensive N+1 queries.
Fast-forward to the end
I'll be honest: there's some side-roads we had to address along the way that I didn't cover above, but in the end, we've gotten to the LOC triggering N+1s calls:
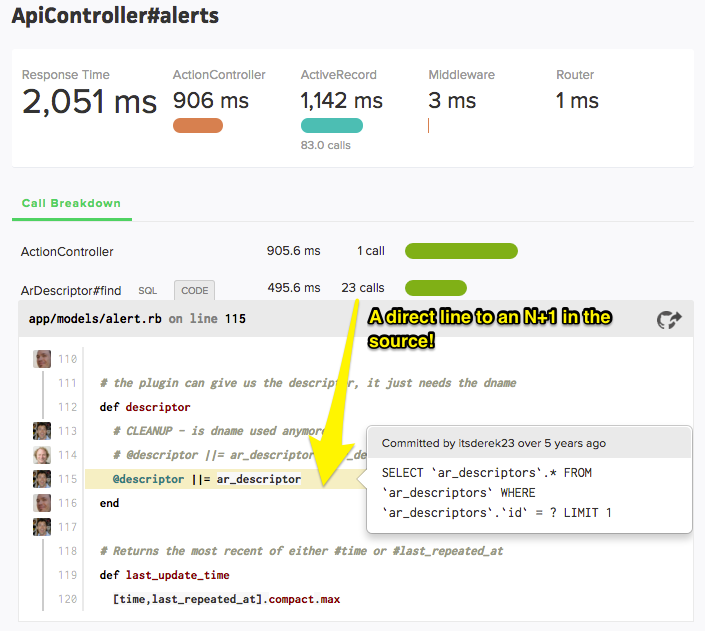
Try Scout's N+1 query detection
N+1 detection is available in version 1.5.0 of our gem. Try Scout for free and let us know how we're doing finding those N+1s. I think you'll be quite happy.
PS - learn more about Stackprof and Rails performance by subscribing to our finally-curated newsletter via the form on the right.




