Docker: Git for deployment

My three takeaways are below.
Finally, an efficient way to simulate our production environment

Our production environment has 16 servers. If I attempted to simulate this locally with VirtualBox's recommended configuration of 512 MB per-instance, this would use about twice the RAM I have on my laptop. VirtualBox has a lot of overhead as each image uses its own kernel and file system. This isn't the case with Docker - containers share the same operating system as the host, and when possible, the same binaries and libraries. It's possible to run hundreds of containers on a single Docker host.
The Old Way
I can't simulate our full environment locally, but lets just look at the time to start a single VM using Vagrant:
$time vagrant up Bringing machine 'default' up with 'virtualbox' provider... [default] Importing base box 'squeeze64-ruby193'... ... [default] Booting VM... [default] Waiting for VM to boot. This can take a few minutes. ... real 1m32.052s
That's over a minute and a half to start a single image. What if I need to make a simple config change and want to verify it works when I restart the image? That's another minute a half.
That is a cruel punishment when you make a mistake.
The Docker Way
Just how lightweight is Docker? When you run processes in a Docker container, you might not even notice they aren't running directly on your host. In the example below, I'm starting a Docker container from an image I've tagged "rails" that runs a Rails App (Dockerfile):
root@precise64:~# docker run rails 2013-08-26 20:21:14,600 CRIT Supervisor running as root (no user in config file) 2013-08-26 20:21:14,603 WARN Included extra file "/srv/docker-rails/Supervisorfile" during parsing 2013-08-26 20:21:14,736 INFO RPC interface 'supervisor' initialized 2013-08-26 20:21:14,740 CRIT Server 'unix_http_server' running without any HTTP authentication checking 2013-08-26 20:21:14,754 INFO supervisord started with pid 1 2013-08-26 20:21:15,783 INFO spawned: 'rails' with pid 10 2013-08-26 20:21:16,841 INFO success: rails entered RUNNING state, process has stayed up for > than 1 seconds (startsecs)
That's just two seconds to start the container and launch supervisor (which starts the Rails app).
In short, Docker goes beyond making it possible for you to simulate your full environment on you development computer. It makes it fast. When it's this easy, hand me the keys: I'll test out the full stack.
Building images is easy and fast - hurray caching!
The Old Way
If you are scripting the process to build a virtual machine image from a base image (example: building the Rails stack on Ubuntu), getting all of the pieces to flow correctly can be a pain if you don't do it frequently. Lets say you install the dependencies for Ruby:
$time apt-get install -y -q ruby1.9.1 ruby1.9.1-dev rubygems1.9.1 irb1.9.1 build-essential libopenssl-ruby1.9.1 libssl-dev zlib1g-dev Reading package lists... Building dependency tree... The following extra packages will be installed: .... Setting up libalgorithm-merge-perl (0.08-2) ... Processing triggers for libc-bin ... ldconfig deferred processing now taking place real 1m22.470s
Then, you try to install the dependencies for NodeJS, but you forget to add the node apt repository:
$apt-get install -y nodejs ... E: Unable to locate package nodejs
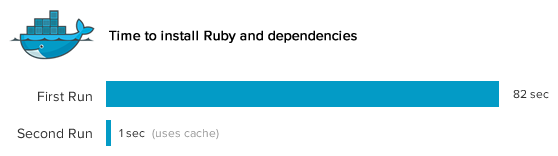
After you fix the NodeJS issue, you still want to be confident your script works on a fresh base image. You'd need to re-run the Ruby install, waiting 82 seconds before the Node install even starts. Painful.
The Docker Way
Put the steps to build an image in a Dockerfile. Dockerfiles are easy to read because you don't need to learn a separate DSL - it's basically just running commands as you enter them. Installing Ruby the first time won't be any faster, but lets take a look what happens when we build the image again from the Dockerfile:
FROM ubuntu:12.04 RUN apt-get update ## MYSQL RUN apt-get install -y -q mysql-client libmysqlclient-dev ## RUBY RUN apt-get install -y -q ruby1.9.1 ruby1.9.1-dev rubygems1.9.1 irb1.9.1 build-essential libopenssl-ruby1.9.1 libssl-dev zlib1g-dev
root@precise64:/# time docker build -t="dlite/appserver" . Uploading context 92160 bytes Step 1 : FROM ubuntu:12.04 ---> 8dbd9e392a96 Step 2 : RUN apt-get update ---> Using cache ---> b55e9ee7b959 Step 3 : RUN apt-get install -y -q mysql-client libmysqlclient-dev ---> Using cache ---> dc92be6158b0 Step 4 : RUN apt-get install -y -q ruby1.9.1 ruby1.9.1-dev rubygems1.9.1 irb1.9.1 build-essential libopenssl-ruby1.9.1 libssl-dev zlib1g-dev ---> Using cache ---> 7038022227c0 Successfully built 7038022227c0 real 0m0.848s
Wow - how did installing Ruby take under one second this time around? See those cache keys (ex: dc92be6158b0)? Rather than re-running the line from the Dockerfile, Docker sees that it has already run that command and just retrieves the file system changes from its cache. It can do this magic because Docker uses the AuFS file system, which is a union file system (kind of like applying diffs).
In short, Docker makes it painless to iteratively build an image as you don't need to wait for previously successful steps to complete again. I'm not perfect and Docker doesn't punish me when I make mistakes.
Deploy images, not infrastructure updates
The Old Way
Like many other deployments today, Scout uses long-running virtual machines. We handle infrastructure updates via Puppet, but this is frequently more painful than we'd like:
- If we're deploying an update to our stack, Puppet will run and update each of our virtual machines. This takes a long time - even though only a small portion of stack may change, Puppet checks everything.
- Problems can happen during a deploy. If we're installing Memcached and there is a network hiccup,
apt-get install memcachedcould fail on some of our servers. - Rolling back major changes often doesn't go as smoothly as we'd like (like updating Ruby versions).
None of these issues are Puppet's fault - a tool like Puppet or Chef is needed when you have long-running VMs that could become inconsistent over time.
The Docker Way
Deploy images - don't modify existing VMs. You'll be 100% sure what runs locally will run on production.
But images are large, right? Not with Docker - remember containers don't run their own guest OS and we're using a union file system. When we make changes to an image, we just need the new layers.
For example, lets say we're installing Memcached onto our app servers. We'll build a new image. I'll tag it as dlite/appserver-memcached, where dlite is my index.docker.io user name. It's based off the dite/appserver image.
root@precise64:/# time docker build -t="dlite/appserver-memcached" . Uploading context 92160 bytes Step 1 : FROM appserver ---> 8dbd9e392a96 Step 2 : RUN apt-get update ---> Using cache ---> b55e9ee7b959 Step 3 : RUN apt-get install -y -q memcached ---> Running in 2a2a689daee3 Reading package lists... Building dependency tree... ... Starting memcached: memcached. Processing triggers for libc-bin ... ldconfig deferred processing now taking place ---> 2a2a689daee3 Successfully built 2a2a689daee3 real 0m13.289s user 0m0.132s sys 0m0.376s
It took just 13 seconds to install Memcached because prior Dockerfile lines were cached. I love speed.
I'll commit and push this:
root@precise64:/# time docker push dlite/appserver-memcached
The push refers to a repository [dlite/appserver-memcached] (len: 1)
Processing checksums
Sending image list
Pushing repository dlite/appserver-memcached (1 tags)
Pushing 8dbd9e392a964056420e5d58ca5cc376ef18e2de93b5cc90e868a1bbc8318c1c
Image 8dbd9e392a964056420e5d58ca5cc376ef18e2de93b5cc90e868a1bbc8318c1c already pushed, skipping
...
Pushing tags for rev [ad8f8a3809afcf0e2cff1af93a8c29275a847609b05b20f7b6d2a5cbd32ff0d8] on {https://registry-1.docker.io/v1/repositories/dlite/appserver-memcached/tags/latest}
real 0m28.710s
On the production server, I'll pull this image down:
root@prod:/# time docker pull dlite/appserver-memcached Pulling repository dlite/appserver-memcached Pulling image ad8f8a3809afcf0e2cff1af93a8c29275a847609b05b20f7b6d2a5cbd32ff0d8 (latest) from dlite/appserver-memcached real 0m15.749s
It took just 15 seconds to grab the dlite/appserver-memached image. Note the image size is just 10 MB as it uses the appserver image as the base:
root@precise64:~# docker images REPOSITORY TAG ID CREATED SIZE appserver latest 7038022227c0 3 days ago 78.66 MB (virtual 427.9 MB) appserver-memcached latest 77dc850dcccc 16 minutes ago 10.19 MB (virtual 438.1 MB)
We didn't need to pull down the entire image with Memcached, just the changes to add Memcached to the dlite/appserver image.
Most of the time, the changes we make are much smaller, so pulling down new images will be even faster.
This has big implications:
- It's fast to start new Docker containers
-
Pushing+pulling new Docker images is lightweight
Rather than messing with existing running virtual machines, we'll just fire up new containers and stop the old containers.

dlite/appserver-memcached and start containers with the dlite/appserver image again.
It's not all rainbows
Working with short-lived containers introduces a new set of problems - distributed configuration / coordination and service discovery:
- How do we update the HAProxy config when new app server containers are started?
- How do app servers communicate with the database container when a new database container is started?
- How about communicating across Docker hosts?
The upcoming release of Flynn.io, which will use etcd for this, will help. However, these are problems smaller scale deployments didn't have to worry about before.
Putting it all together: Docker is to deployment as Git is to development
Developers are able to leverage Git's performance and flexibility when building applications. Git encourages experiments and doesn't punish you when things go wrong: start your experiments in a branch, if things fall down, just git rebase or git reset. It's easy to start a branch and fast to push it.
Docker encourages experimentation for operations. Containers start quickly. Building images is a snap. Using another images as a base image is easy. Deploying whole images is fast, and last but not least, it's not painful to rollback.
Fast + flexible = deployments are about to become a lot more enjoyable.
What else?
Scout APM helps you find and fix your inefficient and costly code. We automatically identify N+1 SQL calls, memory bloat, and other code-related issues so you can spend less time debugging and more time programming. We have Ruby, Python and Elixir agents.
Ready to optimize your site? Sign up for a free trial.




